AI is everywhere, impact is not
AI is now present across the enterprise: generative AI, conversational interfaces, intelligent search, and workflow assistants helping in forecasting, customer operations, risk checks, and workflow automation
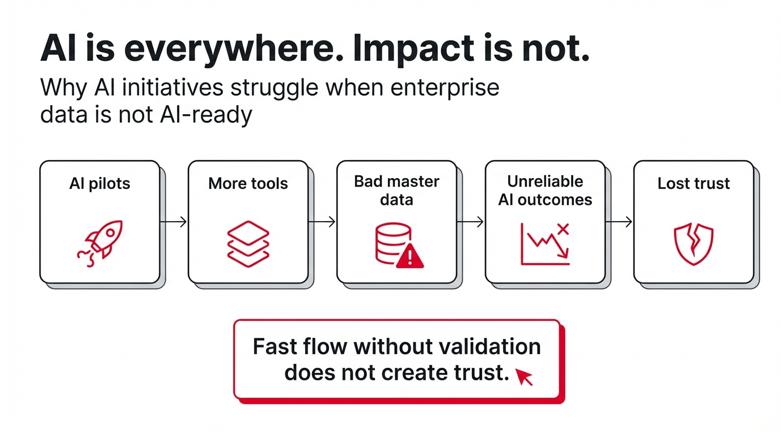
The gap is not the compute. It is not the talent either. And it is rarely the model. The most common constraint is the quality, reliability, and governance of enterprise data, particularly master data such as customers, vendors, products, assets, and employees.
Many organizations are focused on moving data across the systems faster. But speed without validation does not create confidence. This approach ensures flow, not trust.
The Illusion of More Tools and More Intelligence
When AI initiatives do not deliver, the default reaction is to add more capability: a bigger model, a new orchestration layer, another copilot, a new platform.
But AI does not correct weak foundations. It repeats them at scale.
If the underlying data is fragmented, duplicated, incomplete, or inconsistent, an AI layer becomes a faster way to operationalize inconsistency. The outputs may look plausible, but they will not be dependable. In an enterprise context, reliability matters more than novelty.
This is why data readiness keeps emerging as a primary blocker. In Fivetran’s AI and Data Readiness Survey, 42 percent of enterprises said more than half of their AI projects were delayed, underperformed, or failed due to data readiness issues.
Where AI Breaks First is Master Data
When people say “our data is messy,” it sounds broad. In practice, the most damaging issues concentrate on master data.
Master data is the enterprise’s shared memory. It is the “who” and “what” behind every process:
- materials
- customers
- vendors and suppliers
- products and services
- assets
- employees
When master data is unreliable, everything downstream becomes unstable: onboarding, procurement, compliance, analytics, automation, and AI.
Fragmented and Unvalidated Data Sources
Master data enters through many routes: portals, emails, spreadsheets, field teams, distributors, partners, and internal departments. Without shared validation rules, governance and ownership, duplication becomes normal and multiple versions of truth appear quickly.
Manual Effort and Human Error at Scale
Manual entry and scattered checks may work when volumes are small. At scale, minor inconsistencies create real cost: rework, delays, and repeated cleanup cycles that drain time and attention.
Governance Gaps and Compliance Risk
Master records often include compliance-critical details: tax identifiers, licenses, banking information, identity documents. When updates are slow and responsibility is distributed, the risk of outdated or non-compliant data increases.
Periodic Cleansing Cannot Keep Up
Many enterprises still rely on periodic cleanup projects. They improve data quality temporarily, but the issues return because the system continues to accept bad data at the source. This keeps organizations in a costly cycle and delays progress. Source Source
How AI Scales Inconsistency
This is where AI becomes unforgiving.
- If onboarding data is duplicated or incomplete, recommendations become unstable and trust erodes quickly.
- If customer or vendor masters are inconsistent, automation creates downstream rework: rejected records, payment exceptions, broken reporting, and slow onboarding.
- If product and material data are incomplete or duplicated, it creates excess inventory and necessitates multiple sourcing partners. This inefficiency drives revenue loss, increases costs, and creates quality risks due to fragmented sourcing.
- If compliance data is stale, risk compounds quietly because AI output can look plausible even when the foundation is wrong.
IBM frames this plainly: without trusted, high-quality and well-managed data, AI outcomes can be disappointing at best, and inaccurate or risky at worst.
The Root Cause Is Lack of Data Confidence
The issue is rarely that enterprises lack data. The issue is that they lack data confidence: the ability to trust that the organization is operating on a single governed version of truth.
This is also why the idea of a modern data platform is gaining traction. Not to replace ERP or CRM, but to connect systems and make data usable across workflows, analytics, and automation.
In The End
AI success is not primarily an algorithm problem. It is a discipline problem: validating, governing, and owning data at the point it enters the enterprise.
In the next post, we will cover what is needed for AI initiatives to succeed, and what a governed data foundation looks like in practice.
Reflecting on your data landscape: where does your AI pipeline first encounter unvalidated data: customer master, vendor master, or material master?
Where does your AI pipeline first encounter unvalidated data, customer, vendor, or material master?







