AI pilots often look promising in controlled e
nvironments. Then production happens. Real users, real partners, real documents, real exceptions, and real operational pressure expose a familiar gap: AI outcomes are limited by data reality.
Most enterprises do not fail at AI because they chose the wrong model. They struggle because the data feeding those models is inconsistent, incomplete, outdated, or not trusted. The break usually shows up where data first enters the enterprise: vendors, outlets, distributors, customers, gig workers, field teams, and the documents that support them.
In the previous post, we discussed what AI initiatives need to succeed: data confidence, not data volume. This post is about how to operationalize that idea, every day, inside workflows.
The AI problem that rarely looks like an AI problem
When AI initiatives underperform, the symptoms appear as operational friction:
- More manual reviews than expected
- Too many exceptions and rework loops
- Duplicates, mismatches, and “multiple versions of truth” across teams
- Models that drift because the underlying reference data changes without control
AI does not fix messy master data. It amplifies whatever is already there. If poor data makes it into core systems, AI will scale the inconsistency faster.
The job to be done: turn enterprise data into trusted input
If AI is the goal, the practical requirement is straightforward: make sure data is captured once, captured correctly, and stays current.
In operational terms, “AI-ready” data usually means:
- Data is captured at the source with clear definitions and structure
- Validation happens at entry, not weeks later in a cleanup cycle
- Exceptions are resolved through accountable workflows
- Updates stay synchronized across systems
- Governance is continuous, not an annual data quality project
This is the work of building data confidence. And it is where most AI programs quietly win or lose.
What Manch does differently
Many tools digitize tasks. Fewer tools are designed to make data trustworthy while tasks are executed.
Manch is built around a simple premise: if data is governed inside workflows, the enterprise can move faster without losing control. The result is a system where operational processes and master data quality reinforce each other.
A workflow layer built around governed data
When data enters through a governed workflow, the enterprise gets fewer duplicates, fewer incomplete records, and fewer downstream corrections. Instead of relying on back-office cleanup, the organization shifts toward a self and assisted model where data quality is created upstream, closer to the point of capture. In the HCCB case study, the challenges were explicitly tied to lack of validation, re-entries, rejection rates, and delayed turn-around time, and the solution emphasized single source of truth and real-time validation to improve data quality and speed outcomes.
The platform building blocks
Manch is organized into three modules that work together as an operating layer for external stakeholder data:
- MDM: master data integrity for internal and external masters, with validation and governance
- Onboard: structured onboarding for external stakeholders, with verification and controls
- Engage: lifecycle updates and self-service so data stays current over time
This “single source of truth” and no-code configuration approach is positioned as a way to reduce silos and keep external stakeholder data accurate, consistent, and compliant.
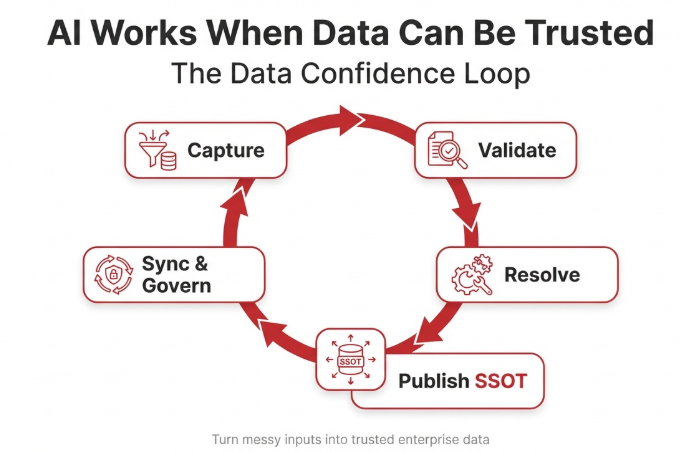
The data confidence loop Manch operationalizes
Enterprises often treat data quality as a downstream activity. Manch treats it as an upstream loop that runs every day.
1) Capture data at the source
External stakeholders submit details and documents through guided flows. The goal is to reduce ambiguity at entry so the first version of the record is usable.
2) Validate in real time
Validation checks prevent bad data from entering core systems. In the HCCB case study, “real-time validation of critical information” and improved data quality are called out as key outcomes, along with a shift toward a single source of truth.
3) Resolve exceptions with workflow
Not everything can be fully automated. The point is to make exceptions visible, routable, and accountable, rather than handled in spreadsheets and email threads.
4) Publish a single version of truth
When teams stop debating which record is correct, execution speeds up. HCCB’s case highlights the move to a single source of truth for master data as part of the solution and results.
5) Keep it current with updates and sync
Many AI issues are not created on day one. They are created on day ninety when details change but systems do not. In the Carlsberg case study, a central requirement was the ability to update KYC information and synchronize changes in real time so the database remained current and accurate.
Proof points from the field
HCCB: reducing rework by fixing validation and control issues upstream
HCCB’s existing MDM setup had gaps that showed up as delayed turn-around time, lack of validation, and weak control over data quality. The case study also notes that more than 40 percent of customer onboarding entries were rejected, with frequent re-entries required due to lack of validation. Manch’s solution emphasized a single source of truth, real-time validation, and improved data quality, with results described as onboarding time improving from days to hours and stronger operational independence.
Carlsberg: scalable vendor onboarding and KYC updates with synchronization
Carlsberg needed bulk onboarding and KYC processes that were faster, less error-prone, and easier to scale. Challenges included manual onboarding and data inaccuracy due to missing update mechanisms. Manch implemented digital onboarding, automated KYC verification, and real-time synchronization of updates to ensure records remained current and accurate, with notifications to reduce the risk of outdated information.
Where built-in AI fits, and why it works better with governed data
Manch also includes built-in AI and ML tools designed to reduce manual intervention and support fraud detection and process optimization. Examples listed include face extraction, face compare, ID detection, and document detection, positioned as integrated components rather than separate third-party add-ons.
This matters for one reason: AI features become more reliable when they operate inside a controlled data loop. A document classifier is more useful when it is part of an onboarding workflow that enforces required fields, validation rules, and exception handling. A face compare check is more useful when identity data is consistently captured, verified, and stored against a stable reference record.
The AI/ML page also presents outcome examples such as reduction in back-office resources, verified KYC, and faster onboarding, reinforcing the theme that AI value is realized when it is tied to operational workflow and data quality controls.
If AI is the goal, what to fix first
For most organizations, the fastest path to better AI outcomes is to improve the data that AI depends on.
A practical starting checklist:
- Identify the master data domains that break AI first (vendor, outlet, customer, material, employee)
- Define validation rules at entry for those domains
- Establish a single version of truth and clarify ownership
- Instrument exceptions and rework so “data friction” becomes measurable
- Ensure update flows exist, so records stay current over time
AI success becomes much more predictable when the enterprise can trust its inputs.
Closing thought
The first post in this series explained why organizations struggle with AI success. The second clarified what is needed: data confidence. This post shows how to put that into practice.
When enterprises make data trustworthy at the point of capture, keep it synchronized through lifecycle updates, and govern it continuously, AI stops being fragile. It becomes operational.







