AI readiness is not a model decision
A lot of AI conversations begin with the same question: which model should we use. It feels like the right place to start, because models are visible. They are easy to demo, easy to compare, and easy to budget for.
But AI readiness is not a model decision. It is a data decision.
Gartner puts it directly: organizations that fail to recognize how AI-ready data differs from traditional data management practices will put their AI efforts at risk. Gartner also predicts that through 2026, organizations will abandon 60 percent of AI projects unsupported by AI-ready data.
This is why the real question is not how much data you have. The question is whether you have data confidence.
The shift from managing systems to managing data
Enterprises already run on systems. ERP, CRM, SCM, procurement suites, HR platforms. Over time, most organizations have collected many systems that each store part of the truth.
The modern shift is not about replacing these systems. It is about connecting them, governing the data they produce, and making that data usable across workflows, analytics, and automation. Source
When data becomes a by-product of applications, the business ends up debating which report is right. When data becomes the core asset, the business can act on what is real.
That is the foundation AI needs.
What AI-ready data looks like in practice
IBM defines AI-ready data as high-quality, accessible, and trusted information that organizations can use confidently for AI training and initiatives. It also lists common barriers such as data sprawl, fragmentation, poor data quality, and governance risks.
Fivetran highlights another operational reality. Even highly centralized organizations report major pipeline maintenance burdens, and many struggle to provide real-time access. In the same survey, Fivetran reports that 42 percent of enterprises say more than half of their AI projects have been delayed, underperformed, or failed due to data readiness issues. Source
So AI-ready data is not just clean data. It is usable data. And it stays usable as the organization changes.
A simple readiness model in six pillars
Here is a practical model that works across industries and use cases. The goal is not perfection. The goal is repeatability.
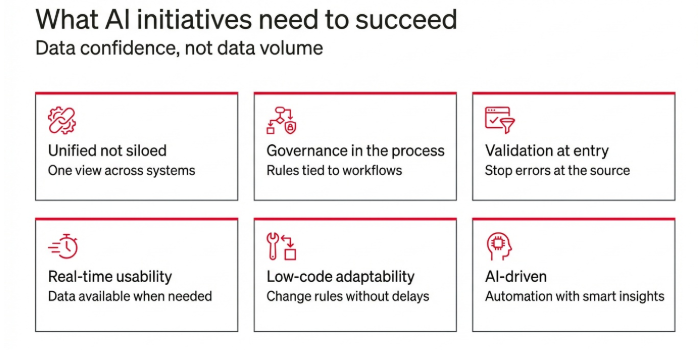
- Unified not siloed
AI cannot work across functions if data remains trapped by system, geography, or department. A modern data platform creates cross-functional trust by reducing duplication and enabling a single view across domains. IBM describes the same requirement as unified and accessible data to support AI readiness.
- Governance embedded in process
Governance cannot live only in policies and committees. It must be tied to workflows and enforced where data is created, updated, and approved. A process-aware approach links governance to how data is used in everyday business.
- Validation at the point of capture
Fixing data after it enters the system keeps organizations in a cleanup cycle. The more scalable approach is validating data at entry using rules, checks, and verification. This addresses the root issue described in Manch’s master data challenges post: fragmented sources, weak validation protocols, and declining data quality.
- Real-time usability across systems
AI initiatives fail quietly when the data needed for a decision is not available in time or cannot be used across systems. Fivetran reports that lack of real-time data access is a common barrier and associates it with stalled AI outcomes.
- Low-code or no-code adaptability
Business rules change. Compliance requirements change. Partner ecosystems change. If every change requires lengthy IT projects, governance becomes slow and adoption suffers. Low-code and no-code adaptability is a core characteristic of modern data platforms because it reduces dependency and improves responsiveness.
- AI-driven governance for duplicates and anomalies
As data volumes increase, manual governance does not scale. Modern platforms use AI-driven governance to detect duplicates, inconsistencies, and anomalies automatically. This is listed as a defining feature in the modern data platform framing
A practical framing using data activation
A useful way to think about readiness is this: the next wave of transformation is not collecting more data. It is making the existing data work across processes.
This is the idea of data activation. It is the point where governance meets execution and where the organization stops treating data as a back-office cleanup problem.
In the next post, we will focus on how to operationalize this foundation. That is where platforms, workflows, validation, and governance come together in day-to-day execution.
If you had to audit your master data today, could you prove it’s validated, current, and compliant?
Master Data ROI Calculator
Calculate the Return on Investment for MDM Solutions







